
|
|
2 年之前 | |
|---|---|---|
| .. | ||
| core | b4790900f5 [RLlib] Sub-class `Trainer` (instead of `build_trainer()`): All remaining classes; soft-deprecate `build_trainer`. (#20725) | 2 年之前 |
| doc | 4e24c805ee AlphaZero and Ranked reward implementation (#6385) | 4 年之前 |
| environments | 026bf01071 [RLlib] Upgrade gym version to 0.21 and deprecate pendulum-v0. (#19535) | 3 年之前 |
| examples | dd70720578 [rllib] Rename sample_batch_size => rollout_fragment_length (#7503) | 4 年之前 |
| models | 28ab797cf5 [RLlib] Deprecate old classes, methods, functions, config keys (in prep for RLlib 1.0). (#10544) | 4 年之前 |
| optimizer | 9a83908c46 [rllib] Deprecate policy optimizers (#8345) | 4 年之前 |
| README.md | 42991d723f [RLlib] rllib/examples folder restructuring (#8250) | 4 年之前 |
| __init__.py | 2e60f0d4d8 [RLlib] Move all jenkins RLlib-tests into bazel (rllib/BUILD). (#7178) | 4 年之前 |
README.md
AlphaZero implementation for Ray/RLlib
Notes
This code implements a one-player AlphaZero agent. It includes the "ranked rewards" (R2) strategy which simulates the self-play in the two-player AlphaZero in forcing the agent to be better than its previous self. R2 is also very helpful to normalize dynamically the rewards.
The code is Pytorch based. It assumes that the environment is a gym environment, has a discrete action space and returns an observation as a dictionary with two keys:
obsthat contains an observation under either the form of a state vector or an imageaction_maskthat contains a mask over the legal actions
It should also implement a get_stateand a set_state function.
The model used in AlphaZero trainer should extend ActorCriticModel and implement the method compute_priors_and_value.
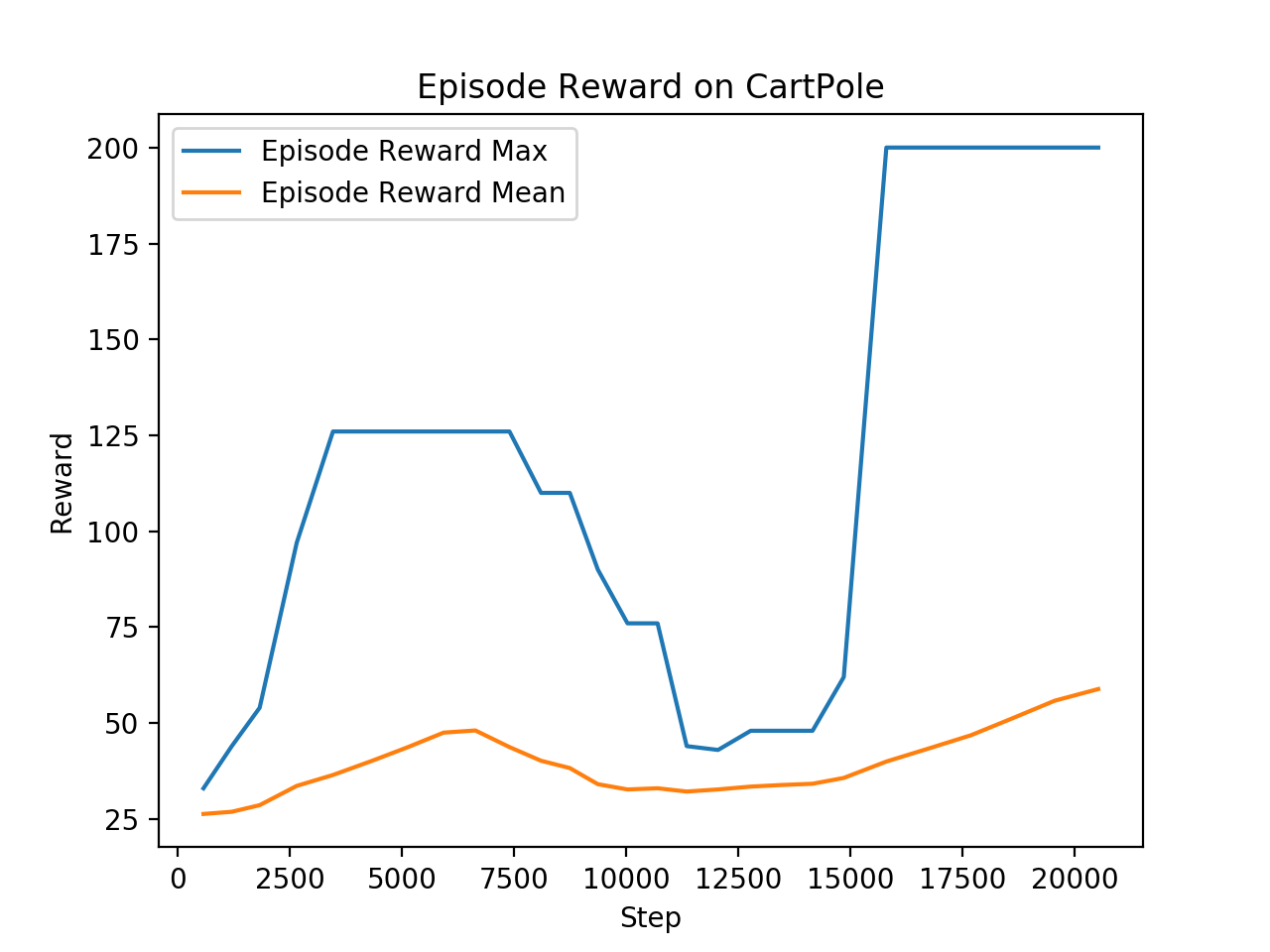
Example on CartPole
Note that both mean and max rewards are obtained with the MCTS in exploration mode: dirichlet noise is added to priors and actions are sampled from the tree policy vectors. We will add later the display of the MCTS in exploitation mode: no dirichlet noise and actions are chosen as tree policy vectors argmax.
References
- AlphaZero: https://arxiv.org/abs/1712.01815
- Ranked rewards: https://arxiv.org/abs/1807.01672