
README.md 20 KB
Berkeley Function Calling Leaderboard (BFCL)
Introduction
We introduce the Berkeley Function Leaderboard (BFCL), the first comprehensive and executable function call evaluation dedicated to assessing Large Language Models' (LLMs) ability to invoke functions. Unlike previous function call evaluations, BFCL accounts for various forms of function calls, diverse function calling scenarios, and their executability.
💡 Read more in our Gorilla OpenFunctions Leaderboard Blogs:
🦍 See the Berkeley Function Calling Leaderboard live at Berkeley Function Calling Leaderboard
Install Dependencies
# Create a new Conda environment with Python 3.10
conda create -n BFCL python=3.10
# Activate the new environment
conda activate BFCL
# Clone the Gorilla repository
git clone https://github.com/ShishirPatil/gorilla.git
# Change directory to the berkeley-function-call-leaderboard
cd gorilla/berkeley-function-call-leaderboard
# Install the package in editable mode
pip install -e .
Installing Extra Dependencies for Self-Hosted Open Source Models
To do LLM generation on self-hosted open source models, you can choose to use vllm or sglang for local inference. Both options require GPUs supported by the respective libraries, and it only works on Linux or Windows, but not on MacOS.
sglang is much faster than vllm but only supports newer GPUs with SM 80+ (Ampere etc).
If you are using an older GPU (T4/V100), you should use vllm instead as it supports a much wider range of GPUs.
Use the following commands to install the necessary dependencies based on your choice:
For Local Inference Using vllm
pip install -e .[oss_eval_vllm]
For Local Inference Using sglang
pip install -e .[oss_eval_sglang]
Note:
If you choose sglang, we recommend also installing the flashinfer package for even faster and more efficient inference.
Depends on the CUDA version, you can find the specific flashinfer installation command here.
Setting up Environment Variables
We use .env file to store the environment variables. We have provided a sample .env.example file in the gorilla/berkeley-function-call-leaderboard directory. You should make a copy of this file, rename it to .env and fill in the necessary values.
cp .env.example .env
API Keys for Execution Evaluation Data Post-processing (Can be Skipped: Necessary for Executable Test Categories)
Add your keys into the .env file, so that the original placeholder values in questions, params, and answers will be reset.
To run the executable test categories, there are 4 API keys to include:
RAPID-API Key: https://rapidapi.com/hub
- Yahoo Finance: https://rapidapi.com/sparior/api/yahoo-finance15
- Real Time Amazon Data : https://rapidapi.com/letscrape-6bRBa3QguO5/api/real-time-amazon-data
- Urban Dictionary: https://rapidapi.com/community/api/urban-dictionary
- Covid 19: https://rapidapi.com/api-sports/api/covid-193
- Time zone by Location: https://rapidapi.com/BertoldVdb/api/timezone-by-location
All the Rapid APIs we use have free tier usage. You need to subscribe to those API providers in order to have the executable test environment setup but it will be free of charge!
- Exchange Rate API:https://www.exchangerate-api.com
- OMDB API: http://www.omdbapi.com/apikey.aspx
- Geocode API: https://geocode.maps.co/
The evaluation script will automatically search for dataset files in the default ./data/ directory and replace the placeholder values with the actual API keys you provided in the .env file.
Evaluating different models on the BFCL
Make sure the model API keys are included in your .env file. Running proprietary models like GPTs, Claude, Mistral-X will require them.
OPENAI_API_KEY=sk-XXXXXX
MISTRAL_API_KEY=
FIREWORKS_API_KEY=
ANTHROPIC_API_KEY=
NVIDIA_API_KEY=nvapi-XXXXXX
YI_API_KEY=
VERTEX_AI_PROJECT_ID=
VERTEX_AI_LOCATION=
COHERE_API_KEY=
DATABRICKS_API_KEY=
DATABRICKS_AZURE_ENDPOINT_URL=
If decided to run locally-hosted model, the generation script uses vLLM and therefore requires GPU for hosting and inferencing. If you have questions or concerns about evaluating OSS models, please reach out to us in our discord channel.
Generating LLM Responses
Use the following command for LLM inference of the evaluation dataset with specific models.
For available options for MODEL_NAME and TEST_CATEGORY, please refer to the Models Available and Available Test Category section below.
If no MODEL_NAME is provided, the model gorilla-openfunctions-v2 will be used by default. If no TEST_CATEGORY is provided, all test categories will be run by default.
For API-hosted models:
bfcl generate --model MODEL_NAME --test-category TEST_CATEGORY --num-threads 1
You can optionally specify the number of threads to use for parallel inference by setting the --num-threads flag to speed up inference for hosted models. The default is 1, which means no parallel inference. The maximum number of parallel inference depends on your API rate limit.
For locally-hosted models:
bfcl generate --model MODEL_NAME --test-category TEST_CATEGORY --backend {vllm,sglang} --num-gpus 1 --gpu-memory-utilization 0.9
You can choose between vllm and sglang as the backend and set the --backend flag; The default is vllm.
You can also specify the number of GPUs to use for inference (multi-GPU tensor parallelism) by setting the --num-gpus flag. The default is 1.
You can also specify the GPU memory utilization by setting the --gpu-memory-utilization flag. The default is 0.9. This is helpful if you encounter out-of-memory issues.
Models Available
Below is a table of models we support to run our leaderboard evaluation against. If the models support function calling (FC), we will follow its function calling format provided by official documentation. Otherwise, we use a consistent system message to prompt the model to generate function calls in the right format. You can also use bfcl models command to list out all available models.
| Model | Type |
|---|---|
| gorilla-openfunctions-v2 | Function Calling |
| claude-3-{opus-20240229,sonnet-20240229,haiku-20240307}-FC | Function Calling |
| claude-3-{opus-20240229,sonnet-20240229,haiku-20240307} | Prompt |
| claude-3-5-sonnet-20240620-FC | Function Calling |
| claude-3-5-sonnet-20240620 | Prompt |
| claude-{2.1,instant-1.2} | Prompt |
| command-r-plus-FC | Function Calling |
| command-r-plus | Prompt |
| databrick-dbrx-instruct | Prompt |
| deepseek-ai/deepseek-coder-6.7b-instruct 💻 | Prompt |
| firefunction-{v1,v2}-FC | Function Calling |
| gemini-1.0-pro-{001,002}-FC | Function Calling |
| gemini-1.0-pro-{001,002} | Prompt |
| gemini-1.5-pro-{001,002}-FC | Function Calling |
| gemini-1.5-pro-{001,002} | Prompt |
| gemini-1.5-flash-{001,002}-FC | Function Calling |
| gemini-1.5-flash-{001,002} | Prompt |
| glaiveai/glaive-function-calling-v1 💻 | Function Calling |
| gpt-3.5-turbo-0125-FC | Function Calling |
| gpt-3.5-turbo-0125 | Prompt |
| gpt-4-{0613,1106-preview,0125-preview,turbo-2024-04-09}-FC | Function Calling |
| gpt-4-{0613,1106-preview,0125-preview,turbo-2024-04-09} | Prompt |
| gpt-4o-2024-08-06-FC | Function Calling |
| gpt-4o-2024-08-06 | Prompt |
| gpt-4o-2024-05-13-FC | Function Calling |
| gpt-4o-2024-05-13 | Prompt |
| gpt-4o-mini-2024-07-18-FC | Function Calling |
| gpt-4o-mini-2024-07-18 | Prompt |
| google/gemma-7b-it 💻 | Prompt |
| google/gemma-2-{2b,9b,27b}-it 💻 | Prompt |
| meetkai/functionary-medium-v3.1-FC | Function Calling |
| meetkai/functionary-small-{v3.1,v3.2}-FC | Function Calling |
| meta-llama/Meta-Llama-3-{8B,70B}-Instruct 💻 | Prompt |
| meta-llama/Llama-3.1-{8B,70B}-Instruct-FC 💻 | Function Calling |
| meta-llama/Llama-3.1-{8B,70B}-Instruct 💻 | Prompt |
| meta-llama/Llama-3.2-{1B,3B}-Instruct-FC 💻 | Function Calling |
| meta-llama/Llama-3.2-{1B,3B}-Instruct 💻 | Prompt |
| open-mixtral-{8x7b,8x22b} | Prompt |
| open-mixtral-8x22b-FC | Function Calling |
| open-mistral-nemo-2407 | Prompt |
| open-mistral-nemo-2407-FC | Function Calling |
| mistral-large-2407-FC | Function Calling |
| mistral-large-2407 | Prompt |
| mistral-medium-2312 | Prompt |
| mistral-small-2402-FC | Function Calling |
| mistral-small-2402 | Prompt |
| mistral-tiny-2312 | Prompt |
| Nexusflow-Raven-v2 | Function Calling |
| NousResearch/Hermes-2-Pro-Llama-3-{8B,70B} 💻 | Function Calling |
| NousResearch/Hermes-2-Pro-Mistral-7B 💻 | Function Calling |
| NousResearch/Hermes-2-Theta-Llama-3-{8B,70B} 💻 | Function Calling |
| snowflake/arctic | Prompt |
| Salesforce/xLAM-1b-fc-r 💻 | Function Calling |
| Salesforce/xLAM-7b-fc-r 💻 | Function Calling |
| Salesforce/xLAM-7b-r 💻 | Function Calling |
| Salesforce/xLAM-8x7b-r 💻 | Function Calling |
| Salesforce/xLAM-8x22b-r 💻 | Function Calling |
| microsoft/Phi-3.5-mini-instruct 💻 | Prompt |
| microsoft/Phi-3-medium-{4k,128k}-instruct 💻 | Prompt |
| microsoft/Phi-3-small-{8k,128k}-instruct 💻 | Prompt |
| microsoft/Phi-3-mini-{4k,128k}-instruct 💻 | Prompt |
| nvidia/nemotron-4-340b-instruct | Prompt |
| THUDM/glm-4-9b-chat 💻 | Function Calling |
| ibm-granite/granite-20b-functioncalling 💻 | Function Calling |
| yi-large-fc | Function Calling |
| MadeAgents/Hammer2.0-{7b,3b,1.5b,0.5b} 💻 | Function Calling |
| Qwen/Qwen2.5-{1.5B,7B}-Instruct 💻 | Prompt |
| Qwen/Qwen2-{1.5B,7B}-Instruct 💻 | Prompt |
| Team-ACE/ToolACE-8B 💻 | Function Calling |
| openbmb/MiniCPM3-4B 💻 | Function Calling |
Here {MODEL} 💻 means the model needs to be hosted locally and called by vllm, {MODEL} means the models that are called API calls. For models with a trailing -FC, it means that the model supports function-calling feature. You can check out the table summarizing feature supports among different models here.
For model names with {.}, it means that the model has multiple versions. For example, we provide evaluation on three versions of GPT-4: gpt-4-0125-preview, gpt-4-1106-preview, and gpt-4-0613.
For Gemini models, you need to provide your VERTEX_AI_PROJECT_ID and VERTEX_AI_LOCATION in the .env file.
For Databrick-DBRX-instruct, you need to create a Databrick Azure workspace and setup an endpoint for inference (provide the DATABRICKS_AZURE_ENDPOINT_URL in the .env file).
Available Test Category
In the following two sections, the optional --test-category parameter can be used to specify the category of tests to run. You can specify multiple categories separated by spaces. Available options include:
- Available test groups (you can also use
bfcl test-categoriescommand to see):all: All test categories.- This is the default option if no test category is provided.
multi_turn: All multi-turn test categories.single_turn: All single-turn test categories.live: All user-contributed live test categories.non_live: All not-user-contributed test categories (the opposite oflive).ast: Abstract Syntax Tree tests.executable: Executable code evaluation tests.python: Tests specific to Python code.non_python: Tests for code in languages other than Python, such as Java and JavaScript.python_ast: Python Abstract Syntax Tree tests.
- Available individual test categories:
simple: Simple function calls.parallel: Multiple function calls in parallel.multiple: Multiple function calls in sequence.parallel_multiple: Multiple function calls in parallel and in sequence.java: Java function calls.javascript: JavaScript function calls.exec_simple: Executable function calls.exec_parallel: Executable multiple function calls in parallel.exec_multiple: Executable multiple function calls in parallel.exec_parallel_multiple: Executable multiple function calls in parallel and in sequence.rest: REST API function calls.irrelevance: Function calls with irrelevant function documentation.live_simple: User-contributed simple function calls.live_multiple: User-contributed multiple function calls in sequence.live_parallel: User-contributed multiple function calls in parallel.live_parallel_multiple: User-contributed multiple function calls in parallel and in sequence.live_irrelevance: User-contributed function calls with irrelevant function documentation.live_relevance: User-contributed function calls with relevant function documentation.multi_turn_base: Base entries for multi-turn function calls.multi_turn_miss_func: Multi-turn function calls with missing function.multi_turn_miss_param: Multi-turn function calls with missing parameter.multi_turn_long_context: Multi-turn function calls with long context.multi_turn_composite: Multi-turn function calls with missing function, missing parameter, and long context.
- If no test category is provided, the script will run all available test categories. (same as
all)
If you want to run the
all,non_live,executableorpythoncategory, make sure to register your REST API keys in the.envfile. This is because Gorilla Openfunctions Leaderboard wants to test model's generated output on real world API!If you do not wish to provide API keys for REST API testing, set
test-categoryto any non-executable category.By setting the
--api-sanity-checkflag, or-cfor short, if the test categories include any executable categories (eg, the test name containsexec), the evaluation process will perform the REST API sanity check first to ensure that all the API endpoints involved during the execution evaluation process are working properly. If any of them are not behaving as expected, we will flag those in the console and continue execution.
Evaluating the LLM generations
Running the Checker
Navigate to the gorilla/berkeley-function-call-leaderboard/bfcl/eval_checker directory and run the eval_runner.py script with the desired parameters. The basic syntax is as follows:
bfcl evaluate --model MODEL_NAME --test-category TEST_CATEGORY
For available options for MODEL_NAME and TEST_CATEGORY, please refer to the Models Available and Available Test Category section.
If no MODEL_NAME is provided, all available model results will be evaluated by default. If no TEST_CATEGORY is provided, all test categories will be run by default.
Example Usage
If you want to run all tests for the gorilla-openfunctions-v2 model, you can use the following command:
bfcl evaluate --model gorilla-openfunctions-v2
If you want to evaluate all offline tests (do not require RapidAPI keys) for OpenAI GPT-3.5, you can use the following command:
bfcl evaluate --model gpt-3.5-turbo-0125 --test-category ast
If you want to run the rest tests for a few Claude models, you can use the following command:
bfcl evaluate --model claude-3-5-sonnet-20240620 claude-3-opus-20240229 claude-3-sonnet-20240229 --test-category rest
If you want to run live_simple and javascript tests for a few models and gorilla-openfunctions-v2, you can use the following command:
bfcl evaluate --model gorilla-openfunctions-v2 claude-3-5-sonnet-20240620 gpt-4-0125-preview gemini-1.5-pro-preview-0514 --test-category live_simple javascript
Model-Specific Optimization
Some companies have proposed some optimization strategies in their models' handler, which we (BFCL) think is unfair to other models, as those optimizations are not generalizable to all models. Therefore, we have disabled those optimizations during the evaluation process by default. You can enable those optimizations by setting the USE_{COMPANY}_OPTIMIZATION flag to True in the .env file.
Contributing
We welcome additions to the Function Calling Leaderboard! To add a new model, please follow these steps:
Review the Base Handler:
- Look at
bfcl/model_handler/base_handler.py. This is the base handler object from which all handlers inherit. - Feel free to examine the existing model handlers; you can likely reuse some of the existing code if your new model outputs in a similar format.
- If your model is OpenAI-compatible, the
OpenAIhandler might be helpful. - If your model is hosted locally,
bfcl/model_handler/oss_model/base_oss_handler.pyis a good starting point.
- If your model is OpenAI-compatible, the
- Look at
Create Your Handler and Define the Following Functions:
__init__: Initialize the model object with the necessary parameters.- Define Necessary Methods:
- For API Endpoint Models:
- Implement all the non-implemented methods under the
FC MethodsorPrompting Methodssections in thebase_handler.pyfile, depending on whether your model is a Function Calling model or a Prompt model. - For Locally Hosted Models:
- You only need to define the
_format_promptmethod. - All other methods under the
Prompting Methodssection in thebase_oss_handler.pyfile have been implemented for you, but you can override them if necessary.
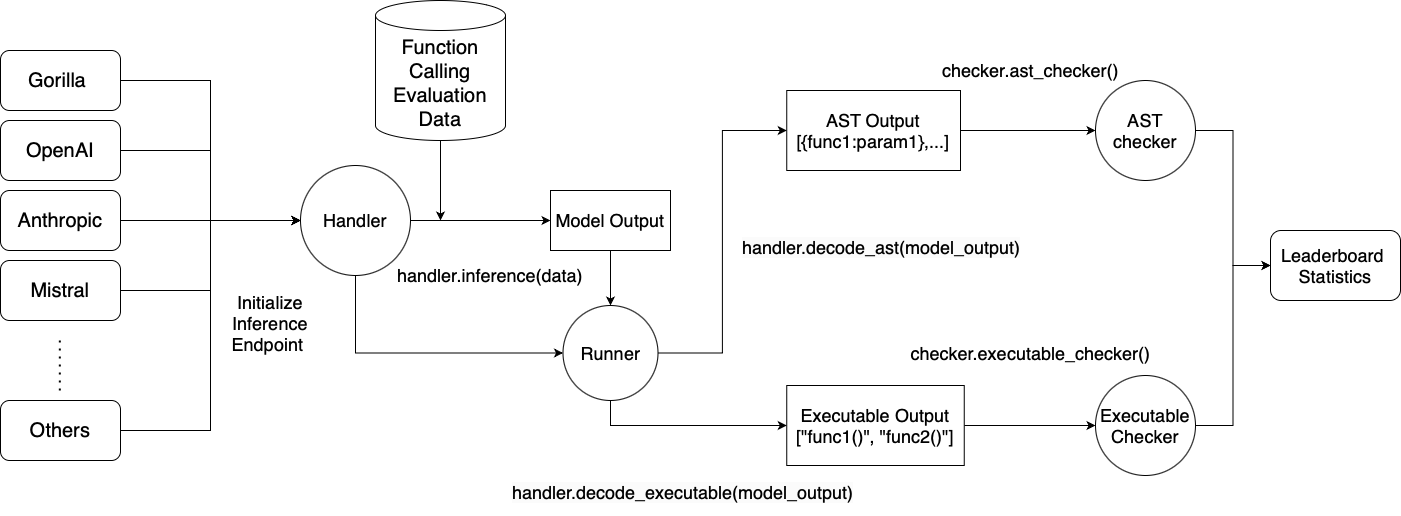
decode_ast: Convert the raw model response to the format[{func1:{param1:val1,...}},{func2:{param2:val2,...}}]; i.e., a list of dictionaries, each representing a function call with the function name as the key and the parameters as the value. This is the format that the evaluation pipeline expects.decode_execute: Convert the raw model response to the format["func1(param1=val1)", "func2(param2=val2)"]; i.e., a list of strings, each representing an executable function call.
Update the Handler Map and Model Metadata:
- Modify
bfcl/model_handler/handler_map.py. This is a mapping of the model name to their handler class. - Modify
bfcl/val_checker/model_metadata.py:- Update the
MODEL_METADATA_MAPPINGwith the model's display name, URL, license, and company information. The key should match the one inbfcl/model_handler/handler_map.py. - If your model is price-based, update the
INPUT_PRICE_PER_MILLION_TOKENandOUTPUT_PRICE_PER_MILLION_TOKEN. - If your model doesn't have a cost, add it to the
NO_COST_MODELSlist. - If your model is open-source and hosted locally, update the
OSS_LATENCYlist with the latency for the entire batch of data generation. This information will affect the cost calculation.
- Update the
- Modify
Submit a Pull Request:
- Raise a Pull Request with your new Model Handler.
- Note that any model on the leaderboard must be publicly accessible—either open-source or with an API endpoint available for inference. While you can require registration, login, or tokens, the general public should ultimately be able to access the endpoint.
Join Our Community:
- Feel free to join the Gorilla Discord
#leaderboardchannel and reach out to us with any questions or concerns about adding new models. We are happy to help you!
- Feel free to join the Gorilla Discord
All the leaderboard statistics, and data used to train the models are released under Apache 2.0. Gorilla is an open source effort from UC Berkeley and we welcome contributors. Please email us your comments, criticisms, and questions. More information about the project can be found at https://gorilla.cs.berkeley.edu/