
README_ja.md 13 KB
![]()
Umi-OCR





![]()
Windows7 x64以上と互換性があります
- 無料: このプロジェクトのすべてのコードはオープンソースで完全に無料です。
- 便利: 解凍して使用し、オフラインで実行し、ネットワークは必要ありません。
- 効率的: 高効率のオフライン OCR エンジンが付属しています。コンピュータのパフォーマンスが十分であれば、オンライン OCR サービスよりも速くなることがあります。
- 柔軟: カスタマイズ可能なインターフェースをサポートし、コマンドラインや HTTP API など、複数の呼び出し方法をサポートします。
ソースコードの使用:
開発者は続ける前に、プロジェクトのビルドを読んでください
リリースのダウンロード:
- GitHub https://github.com/hiroi-sora/Umi-OCR/releases/latest
- Source Forge https://sourceforge.net/projects/umi-ocr
- Lanzou (蓝奏云) https://hiroi-sora.lanzoul.com/s/umi-ocr
• Scoop インストーラー
Scoop はWindowsで動作するコマンドラインインストーラーで、複数のアプリケーションを簡単に管理できます。まず Scoop をインストールし、次に以下のコマンドを使用して Umi-OCR をインストールしてください:
extrasバケットを追加:scoop bucket add extras(オプション1)Umi-OCR をインストール(
Rapid-OCRエンジン付属、互換性が高い):scoop install extras/umi-ocr(オプション2)Umi-OCR をインストール(
Paddle-OCRエンジン付属、やや高速):scoop install extras/umi-ocr-paddle両方を同時にインストールしないでください。ショートカットが上書きされる可能性があります。しかし、プラグイン を追加することで、異なるOCRエンジンをいつでも切り替えることができます。
はじめに
ソフトウェアリリースパッケージは、.7z圧縮形式または自己解凍.7z.exeパッケージで利用可能です。自己解凍パッケージは、圧縮ソフトウェアがインストールされていないコンピューターでファイルを抽出するために使用できます。
このソフトウェアはインストールを必要としません。抽出後、Umi-OCR.exeをクリックしてプログラムを開始します。
問題が発生した場合は、Issueを提出してください。最善を尽くしてサポートします。
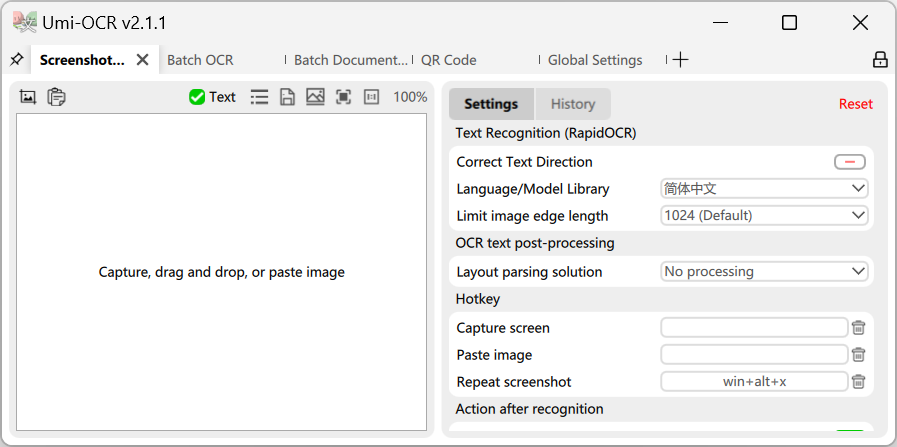
インターフェース言語
Umi-OCR は、インターフェースの複数の言語をサポートしています。ソフトウェアを初めて開くと、コンピューターのシステム設定に基づいて自動的に言語が切り替わります。
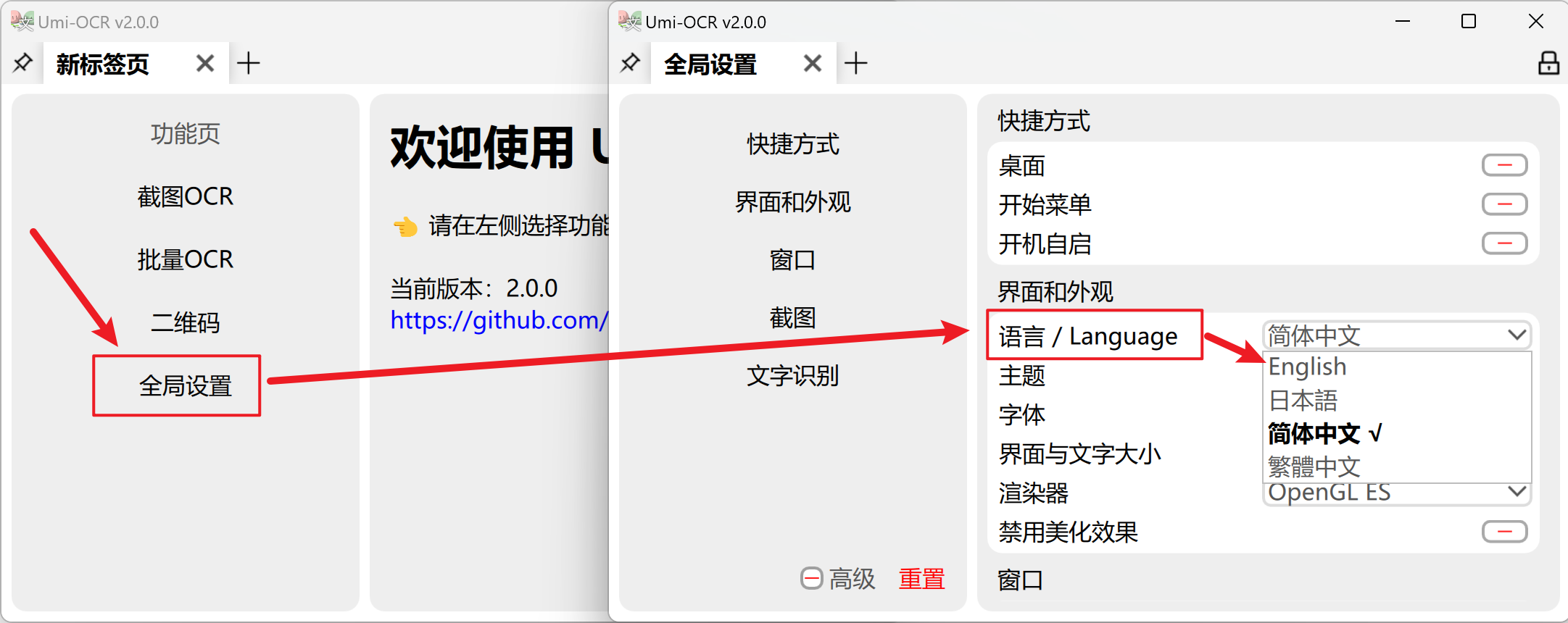
言語を手動で切り替える必要がある場合は、以下の図を参照してください。全局设置→语言/Language。
翻訳を手伝ってください
Weblate オンラインで翻訳作業に参加できます:
https://hosted.weblate.org/engage/umi-ocr/
タブインターフェース
Umi-OCR v2 は、一連の柔軟で使いやすいタブインターフェースで構成されています。好みに応じて必要なタブインターフェースを開くことができます。
タブバーの左上隅を使用してウィンドウ常に最前面を切り替えることができます。右上隅は、日常使用中の偶発的な閉鎖を防ぐためにタブインターフェースをロックするために使用できます。
スクリーンショット OCR
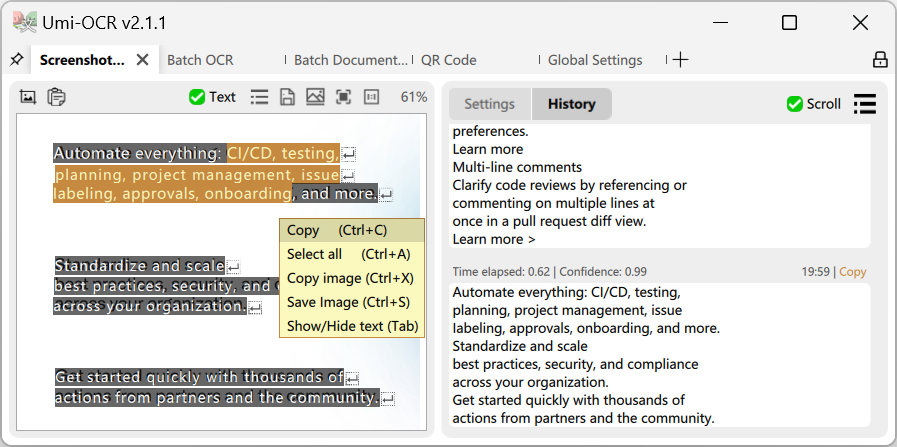
スクリーンショット OCR: このページを開いた後、キーボードショートカットを使用してスクリーンショットをキャプチャし、画像内のテキストを認識することができます。
- 左側の画像プレビューパネルを使用して、マウスでテキストを選択してコピーすることができます。
- 右側の認識レコードパネルを使用して、テキストを編集し、複数のレコードを選択してコピーすることができます。
- 他の場所から画像をコピーして Umi-OCR に貼り付け、認識することもサポートしています。
段落マージ
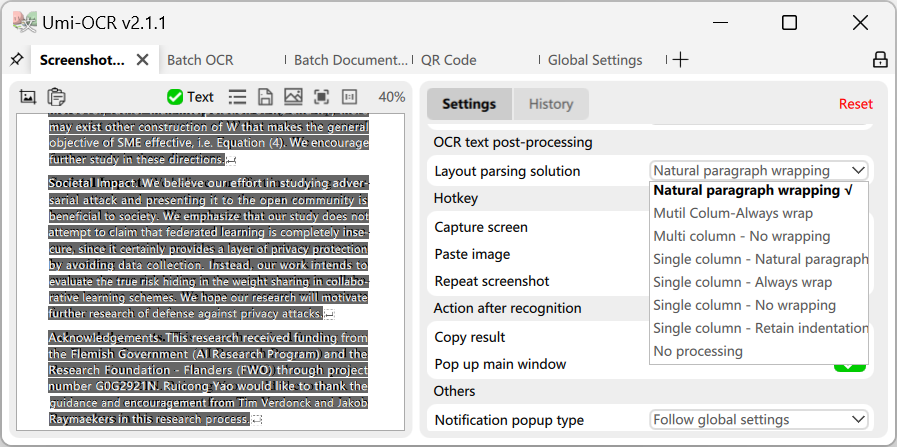
OCR テキスト後処理 - 段落マージについて: この機能は、OCR 結果のレイアウトと順序を整理し、テキストを読みやすく使用しやすくすることができます。プリセットスキームは以下の通りです。
- 単一行: 同じ行上のテキストをマージします。ほとんどのシナリオに適しています。
- 複数行 - 自然な段落: 同じ段落に属するテキストを知的に認識してマージします。ほとんどのシナリオに適しており、上記の図に示されています。
- 複数行 - コードブロック: テキストの元のインデントとスペーシングを復元しようとします。コードスニペットやスペースを保持する必要があるシーンを認識するのに適しています。
- 縦書きレイアウト: 縦書きレイアウトに適しています。縦書き認識もサポートするモデルライブラリと併用する必要があります。
バッチ OCR
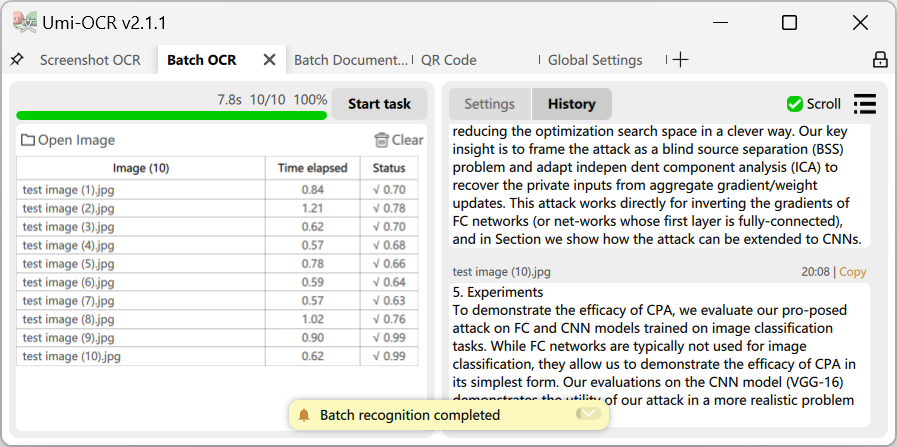
バッチ OCR: このページでは、ローカル画像をバッチでインポートして認識することがサポートされています。
- 認識されたコンテンツは、txt/jsonl/md/csv(Excel)などのさまざまな形式で保存できます。
テキスト後処理技術をサポートし、同じ自然な段落に属するテキストを認識してマージすることができます。また、コードブロックや縦書きテキストなど、複数の処理スキームもサポートしています。- 一度に処理できる画像の数に制限はなく、タスクを完了した後、ソフトウェアは自動的にシャットダウンまたはスリープすることができます。
無視域
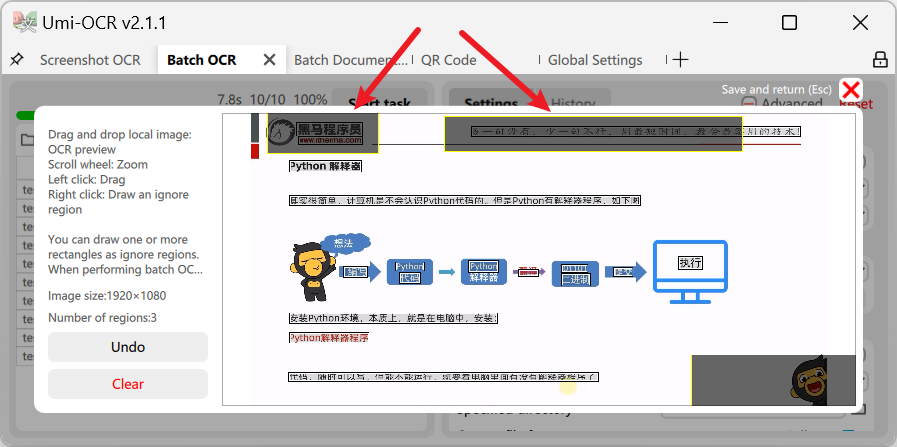
OCR テキスト後処理 - 無視域について: これは、バッチ OCR の特別な機能で、画像内の望ましくないテキストを除外するために使用されます。
- 無視領域エディタは、バッチ認識ページ設定の右側の列でアクセスできます。
- 上記の例のように、画像の上部と右下隅に複数の透かし/LOGO があります。これらの画像がバッチで認識される場合、透かしは認識結果に干渉します。
- 右マウスボタンを押し続けて、複数の長方形ボックスを描画します。これらのエリア内のテキストは、タスク中に無視されます。
- 長方形ボックスをできるだけ大きく描画し、透かしのすべての可能な位置を完全に包むようにしてください。
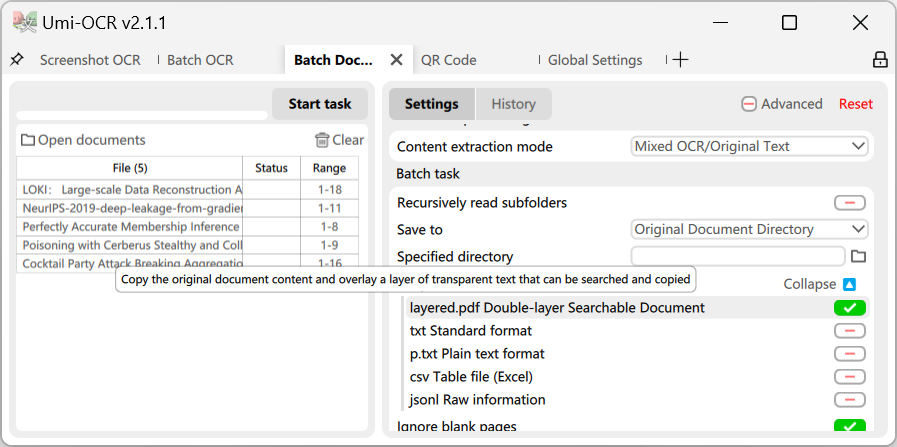
大量文章のocr
QR コード
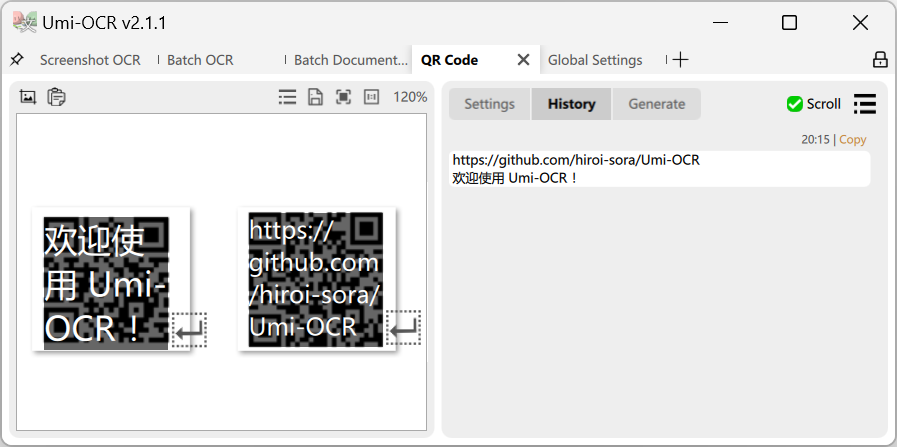
スキャンコード:
- スクリーンショットをキャプチャしたり、貼り付けたり、ローカル画像をドラッグして、QR コードやバーコードを読み取ることができます。
- 1 つの画像で複数のコードをサポートします。
- 以下の 19 のプロトコルをサポートします:
Aztec,Codabar,Code128,Code39,Code93,DataBar,DataBarExpanded,DataMatrix,EAN13,EAN8,ITF,LinearCodes,MatrixCodes,MaxiCode,MicroQRCode,PDF417,QRCode,UPCA,UPCE,
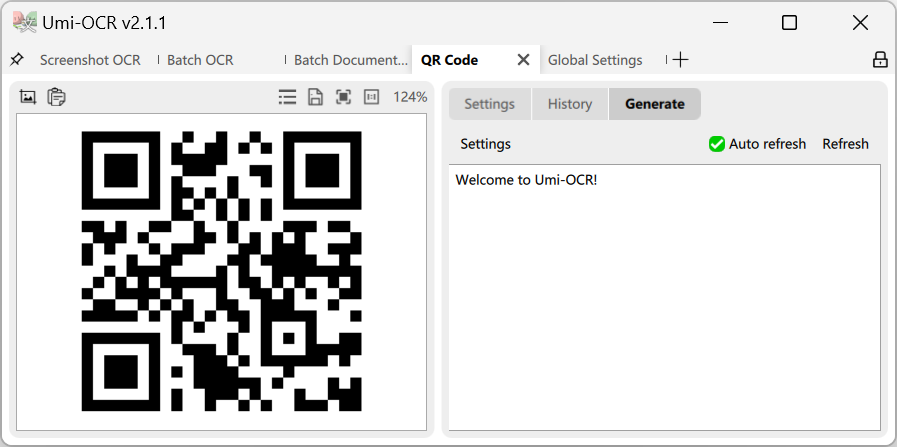
コード生成:
- テキストを入力して QR コード画像を生成します。
- 誤り訂正レベルなどのパラメータを含む 19 のプロトコルをサポートします。
グローバル設定
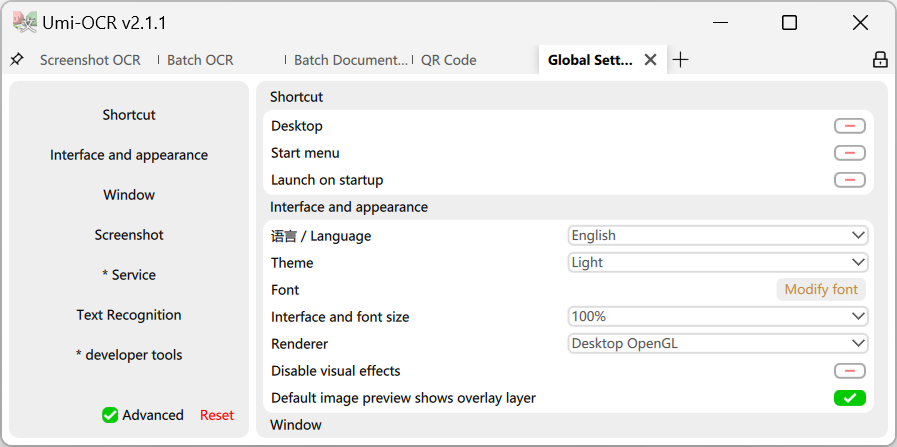
グローバル設定: ここでは、ソフトウェアのグローバルパラメータを調整できます。一般的な機能には、以下が含まれます:
- ショートカットを一度に追加するか、自動起動を設定します。
- インターフェースの言語を変更します。Umi は繁体字中国語、英語、日本語などの言語をサポートしています。
- インターフェースのテーマを切り替えます。Umi には複数のライト/ダークテーマがあります。
- インターフェーステキストのフォントサイズとフォントを調整します。
- OCR プラグインを切り替えます。
- レンダラー: ソフトウェアインターフェースは、デフォルトで GPU 加速レンダリングをサポートしています。画面のちらつきや UI の位置ずれが発生する場合は、
インターフェースと外観→レンダラーに移動して、異なるレンダリングスキームに切り替えるか、ハードウェアアクセラレーションをオフにしてみてください。
API の使用:
プロジェクト構造について
リポジトリ:
プロジェクトのビルド
ステップ 0: (オプション) このプロジェクトをフォークする
ステップ 1: コードをダウンロードする
以下のいずれかを選択してください:
- フォークしたリポジトリをローカルマシンにプルする
- このリポジトリの zip ソースコードパッケージをダウンロードする
- このリポジトリをクローンする
次のステップ:
対応するプラットフォームの開発/ランタイム環境デプロイメントを完了するには、以下のリポジトリに進んでください。
このプロジェクトには、非常にシンプルなワンクリックパッケージングスクリプトもあり、以下のリポジトリで見つけることができます。
- Windows
- クロスプラットフォームサポートは開発中です。