
README.md 12 KB

Website & Demo | Discord | Paper [coming April 2024]
👋 Overview
SWE-agent turns LMs (e.g. GPT-4) into software engineering agents that can fix bugs and issues in real GitHub repositories.
On SWE-bench, SWE-agent resolves 12.29% of issues, achieving the state-of-the-art performance on the full test set.
SWE-agent is built and maintained by researchers from Princeton University.
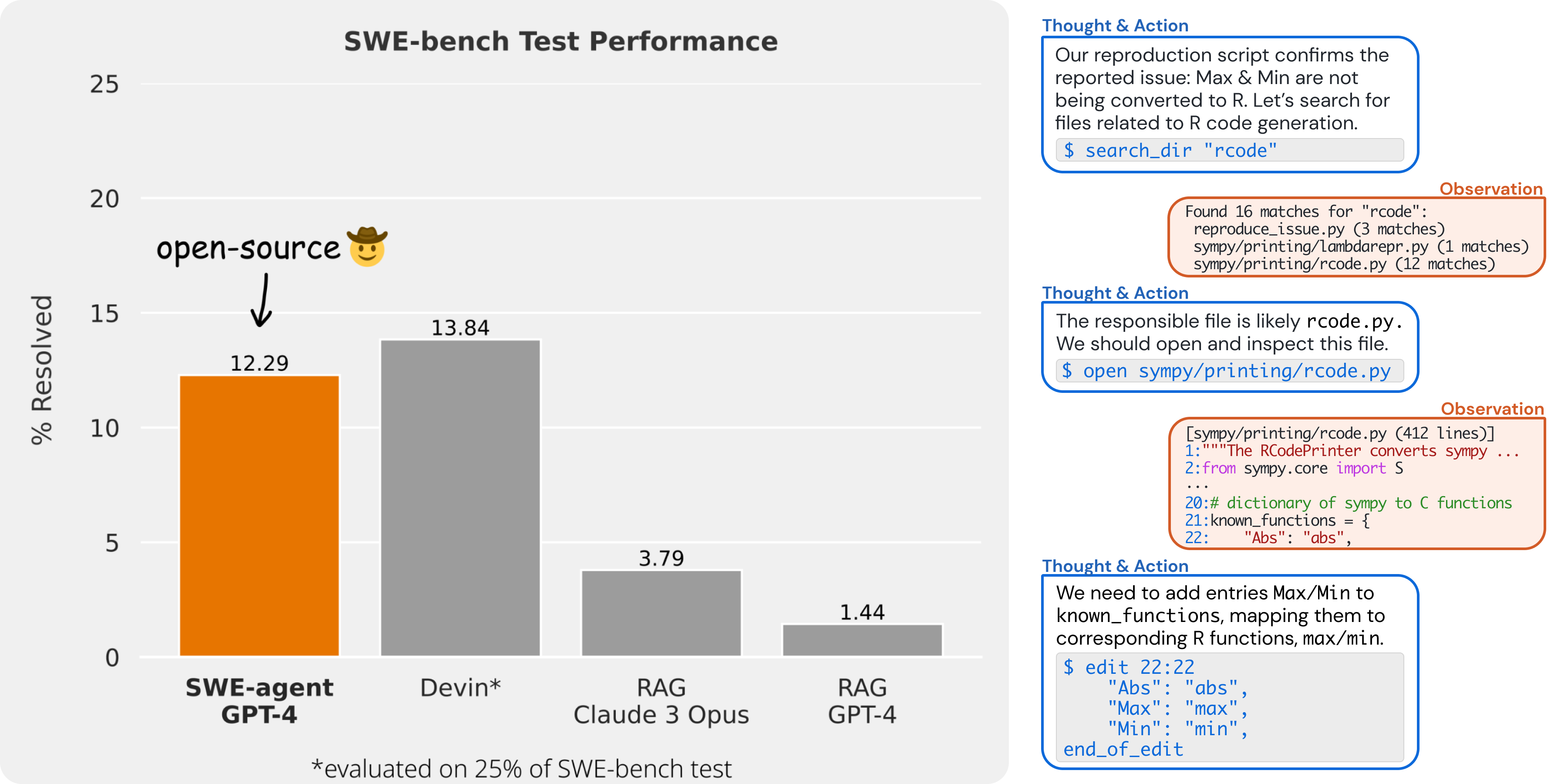
✨ Agent-Computer Interface (ACI)
We accomplish these results by designing simple LM-centric commands and feedback formats to make it easier for the LM to browse the repository, view, edit and execute code files. We call this an Agent-Computer Interface (ACI) and build the SWE-agent repository to make it easy to iterate on ACI design for repository-level coding agents.
Just like how typical language models requires good prompt engineering, good ACI design leads to much better results when using agents. As we show in our paper, a baseline agent without a well-tuned ACI does much worse than SWE-agent.
SWE-agent contains features that we discovered to be immensely helpful during the agent-computer interface design process:
- We add a linter that runs when an edit command is issued, and do not let the edit command go through if the code isn't syntactically correct.
- We supply the agent with a special-built file viewer, instead of having it just
catfiles. We found that this file viewer works best when displaying just 100 lines in each turn. The file editor that we built has commands for scrolling up and down and for performing a search within the file. - We supply the agent with a special-built full-directory string searching command. We found that it was important for this tool to succintly list the matches- we simply list each file that had at least one match. Showing the model more context about each match proved to be too confusing for the model.
- When commands have an empty output we return a message saying "Your command ran successfully and did not produce any output."
Read our paper for more details [coming soon!].
@misc{yang2024sweagent,
title={SWE-agent: Agent Computer Interfaces Enable Software Engineering Language Models},
author={John Yang and Carlos E. Jimenez and Alexander Wettig and Shunyu Yao and Karthik Narasimhan and Ofir Press},
year={2024},
}
🚀 Setup
🏎️ Express Setup + Run
You can run the software directly using Docker.
- Install Docker, then start Docker locally.
- Run
docker pull --platform=linux/arm64 sweagent/swe-agent:latest(replacearm64withamd64if you're running on x86) - Add your API tokens to a file
keys.cfgas explained below
Then run
# Please remove all comments (lines starting with '#') before running this command!
docker run --rm -it -v /var/run/docker.sock:/var/run/docker.sock \
# replace /xxxx/keys.cfg with the paths to your keys
-v /xxxx/keys.cfg:/app/keys.cfg \
# replace with your architecture, either arm64 or amd64
--platform=linux/arm64 \
sweagent/swe-agent-run:latest \
python run.py --image_name=sweagent/swe-agent:latest \
# the rest of the command as shown in the quickstart/benchmarking section,
# for example to run on a specific github issue
--model_name gpt4 \
--data_path https://github.com/pvlib/pvlib-python/issues/1603 \
--config_file config/default_from_url.yaml --skip_existing=False
[!TIP]
- For more information on the different API keys/tokens, see below.
- If you're using docker on Windows, use
-v //var/run/docker.sock:/var/run/docker.sock(double slash) to escape it (more information).- See the installation issues section for more help if you run into trouble.
🐍 Setup with conda (development version)
To install the development version:
- Install Docker, then start Docker locally.
- Clone this repository
- Install Miniconda, then create the
swe-agentenvironment withconda env create -f environment.yml - Activate using
conda activate swe-agent. - Run
./setup.shto create theswe-agentdocker image. - Create a
keys.cfgfile at the root of this repository (see below)
[!WARNING] Expect some issues with Windows (we're working on them). In the meantime, simply use Docker (see above). If you want the latest version, you can also build your own
swe-agent-runcontainer with theDockerfileat the root of this repository by runningdocker build -t sweagent/swe-agent-run:latest .[!TIP] If you run into docker issues, see the installation issues section for more help
🔑 Add your API keys/tokens
For the conda setup, create a keys.cfg file at the root of this repository and populate it with your API keys.
GITHUB_TOKEN: 'GitHub Token Here (required)'
OPENAI_API_KEY: 'OpenAI API Key Here if using OpenAI Model (optional)'
If you're using docker, pass the key with the -e option to the docker container.
🔎 More options for different keys (click to unfold)
All keys are optional.
GITHUB_TOKEN: 'GitHub Token Here'
OPENAI_API_KEY: 'OpenAI API Key Here if using OpenAI Model'
ANTHROPIC_API_KEY: 'Anthropic API Key Here if using Anthropic Model'
TOGETHER_API_KEY: 'Together API Key Here if using Together Model'
AZURE_OPENAI_API_KEY: 'Azure OpenAI API Key Here if using Azure OpenAI Model'
AZURE_OPENAI_ENDPOINT: 'Azure OpenAI Endpoint Here if using Azure OpenAI Model'
AZURE_OPENAI_DEPLOYMENT: 'Azure OpenAI Deployment Here if using Azure OpenAI Model'
AZURE_OPENAI_API_VERSION: 'Azure OpenAI API Version Here if using Azure OpenAI Model'
OPENAI_API_BASE_URL: 'LM base URL here if using Local or alternative api Endpoint'
See the following links for tutorials on obtaining Anthropic, OpenAI, and Github tokens.
More installation tips
If you seem to be having issues with running docker
- Make sure that you allow the use of the Docker socket. In Docker desktop, click Settings > Advanced > Allow the default Docker socket to be used (requires password)
- If your docker installation uses a different socket, you might have to symlink them, see this command for example
Any remaining issues? Please open a GitHub issue!
🔥 Quickstart: Solve real-life GitHub issues!
Using this script, you can run SWE-agent on any GitHub issue!
python run.py --model_name gpt4 \
--data_path https://github.com/pvlib/pvlib-python/issues/1603 \
--config_file config/default_from_url.yaml
[!TIP] You can have the agent automatically open a PR if the issue has been solved by supplying the
--open_prflag. Please use this feature responsibly (on your own repositories or after careful consideration).[!TIP] Run
python run.py --helpto see all available options.
- See the
scripts/folder for other useful scripts and details. - See the
config/folder for details about how you can define your own configuration! - See the
sweagent/agent/folder for details about the logic behind configuration based workflows. - See the
sweagent/environment/folder for details about theSWEEnvenvironment (interface + implementation). - See the
trajectories/folder for details about the output ofrun.py.
Ollama Support
Models served with an ollama server can be used by specifying --model with ollama:model_name and --host_url to point to the url used to serve ollama (http://localhost:11434 by default). See more details about using ollama here.
python run.py --model_name ollama:deepseek-coder:6.7b-instruct \
--host_url http://localhost:11434 \
--data_path https://github.com/pvlib/pvlib-python/issues/1603 \
--config_file config/default_from_url.yaml
💽 Benchmarking
There are two steps to the SWE-agent pipeline. First SWE-agent takes an input GitHub issue and returns a pull request that attempts to fix it. We call that step inference. The second step (currently, only available for issues in the SWE-bench benchmark) is to evaluate the pull request to verify that it has indeed fixed the issue.
[!WARNING] At this moment, there are known issues with a small number of repositories that don't install properly for
arm64/aarch64architecture computers. We're working on a fix, but if you'd like to run and evaluate on the entirety of SWE-bench, the easiest way is by using anx86machine.
👩💻 Inference
Inference on any GitHub Issue: See above.
Inference on SWE-bench: Run SWE-agent on SWE-bench Lite and generate patches.
python run.py --model_name gpt4 \
--per_instance_cost_limit 2.00 \
--config_file ./config/default.yaml
If you'd like to run on a single issue from SWE-bench, use the --instance_filter option as follows:
python run.py --model_name gpt4 \
--instance_filter marshmallow-code__marshmallow-1359
🧪 Evaluation
This step is only available for issues from the SWE-bench set. To evaluate generated pull requests:
cd evaluation/
./run_eval.sh <predictions_path>
Replace <predictions_path> with the path to the model's predictions, which should be generated from the Inference step. The <predictions_path> arguments should look like ../trajectories/<username>/<model>-<dataset>-<hyperparams>/all_preds.jsonl
- See the
evaluation/folder for details about how evaluation works.
💫 Contributions
- If you'd like to ask questions, learn about upcoming features, and participate in future development, join our Discord community!
- If you'd like to contribute to the codebase, we welcome issues and pull requests!
- If you'd like to see a post or tutorial about some topic, please let us know via an issue.
Contact person: John Yang and Carlos E. Jimenez (Email: {jy1682, carlosej}@princeton.edu).
🪪 License
MIT. Check LICENSE.