
index.md 20 KB
layout: single toc: true
toc_label: "Contents"
DeepSpeed is hiring, come join us!
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
10x Larger Models
10x Faster Training
Minimal Code Change
DeepSpeed delivers extreme-scale model training for everyone, from data scientists training on massive supercomputers to those training on low-end clusters or even on a single GPU:
- Extreme scale: Using current generation of GPU clusters with hundreds of devices, 3D parallelism of DeepSpeed can efficiently train deep learning models with trillions of parameters.
- Extremely memory efficient: With just a single GPU, ZeRO-Offload of DeepSpeed can train models with over 10B parameters, 10x bigger than the state of arts, democratizing multi-billion-parameter model training such that many deep learning scientists can explore bigger and better models.
- Extremely long sequence length: Sparse attention of DeepSpeed powers an order-of-magnitude longer input sequence and obtains up to 6x faster execution comparing with dense transformers.
- Extremely communication efficient: 3D parallelism improves communication efficiency allows users to train multi-billion-parameter models 2–7x faster on clusters with limited network bandwidth. 1-bit Adam/1-bit LAMB reduce communication volume by up to 5x while achieving similar convergence efficiency to Adam/LAMB, allowing for scaling to different types of GPU clusters and networks.
Early adopters of DeepSpeed have already produced a language model (LM) with over 17B parameters called Turing-NLG, establishing a new SOTA in the LM category.
DeepSpeed is an important part of Microsoft’s new AI at Scale initiative to enable next-generation AI capabilities at scale, where you can find more information here.
What's New?
- [2021/08/18] DeepSpeed powers 8x larger MoE model training with high performance
- [2021/08/16] Curriculum learning: a regularization method for stable and 2.6x faster GPT-2 pre-training with 8x/4x larger batch size/learning rate
- [2021/05/24] DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression
- [2021/04/20] 1-bit LAMB: up to 4.6x less communication and 2.8x faster training, together with LAMB's convergence speed at large batch sizes
- [2021/04/19] ZeRO-Infinity unlocks unprecedented model scale for deep learning training
- [2021/04/02] [DeepSpeed on AzureML] Transformers and CIFAR examples are now available on AzureML GitHub
- [2021/03/30] [PyTorch Lightning Blog] Accessible Multi-Billion Parameter Model Training with PyTorch Lightning + DeepSpeed
- [2021/03/16] 1-bit Adam v2: NCCL-based implementation and more
- [2021/03/08] ZeRO-3 Offload: Scale your models to trillion parameters without code changes while leveraging both CPUs & GPUs
- [2021/01/19] [🤗Hugging Face Blog] Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
Why DeepSpeed?
Training advanced deep learning models is challenging. Beyond model design, model scientists also need to set up the state-of-the-art training techniques such as distributed training, mixed precision, gradient accumulation, and checkpointing. Yet still, scientists may not achieve the desired system performance and convergence rate. Large model sizes are even more challenging: a large model easily runs out of memory with pure data parallelism and it is difficult to use model parallelism. DeepSpeed addresses these challenges to accelerate model development and training.
Distributed, Effective, and Efficient Training with Ease
The DeepSpeed API is a lightweight wrapper on PyTorch. This means that you can use everything you love in PyTorch and without learning a new platform. In addition, DeepSpeed manages all of the boilerplate state-of-the-art training techniques, such as distributed training, mixed precision, gradient accumulation, and checkpoints so that you can focus on your model development. Most importantly, you can leverage the distinctive efficiency and effectiveness benefit of DeepSpeed to boost speed and scale with just a few lines of code changes to your PyTorch models.
Speed
DeepSpeed achieves high performance and fast convergence through a combination of efficiency optimizations on compute/communication/memory/IO and effectiveness optimizations on advanced hyperparameter tuning and optimizers. For example:
- DeepSpeed trains BERT-large to parity in 44 mins using 1024 V100 GPUs (64 DGX-2 boxes) and in 2.4 hours using 256 GPUs (16 DGX-2 boxes).
BERT-large Training Times
| Devices | Source | Training Time | | -------------- | --------- | ---------------------:| | 1024 V100 GPUs | DeepSpeed | 44 min| | 256 V100 GPUs | DeepSpeed | 2.4 hr| | 64 V100 GPUs | DeepSpeed | 8.68 hr| | 16 V100 GPUs | DeepSpeed | 33.22 hr|
BERT codes and tutorials will be available soon.
- DeepSpeed trains GPT2 (1.5 billion parameters) 3.75x faster than state-of-art, NVIDIA Megatron on Azure GPUs.
Read more: GPT tutorial
Memory efficiency
DeepSpeed provides memory-efficient data parallelism and enables training models without model parallelism. For example, DeepSpeed can train models with up to 13 billion parameters on a single GPU. In comparison, existing frameworks (e.g., PyTorch's Distributed Data Parallel) run out of memory with 1.4 billion parameter models.
DeepSpeed reduces the training memory footprint through a novel solution called Zero Redundancy Optimizer (ZeRO). Unlike basic data parallelism where memory states are replicated across data-parallel processes, ZeRO partitions model states and gradients to save significant memory. Furthermore, it also reduces activation memory and fragmented memory. The current implementation (ZeRO-2) reduces memory by up to 8x relative to the state-of-art. You can read more about ZeRO in our paper, and in our blog posts related to ZeRO-1 and ZeRO-2.
With this impressive memory reduction, early adopters of DeepSpeed have already produced a language model (LM) with over 17B parameters called Turing-NLG, establishing a new SOTA in the LM category.
For model scientists with limited GPU resources, ZeRO-Offload leverages both CPU and GPU memory for training large models. Using a machine with a single GPU, our users can run models of up to 13 billion parameters without running out of memory, 10x bigger than the existing approaches, while obtaining competitive throughput. This feature democratizes multi-billion-parameter model training and opens the window for many deep learning practitioners to explore bigger and better models.
Scalability
DeepSpeed supports efficient data parallelism, model parallelism, pipeline parallelism and their combinations, which we call 3D parallelism.
- 3D parallelism of DeepSpeed provides system support to run models with trillions of parameters, read more in our press-release and tutorial.
- DeepSpeed can run large models more efficiently, up to 10x faster for models with various sizes spanning 1.5B to hundred billion. More specifically, the data parallelism powered by ZeRO is complementary and can be combined with different types of model parallelism. It allows DeepSpeed to fit models using lower degree of model parallelism and higher batch size, offering significant performance gains compared to using model parallelism alone.
Read more: ZeRO paper, and GPT tutorial.
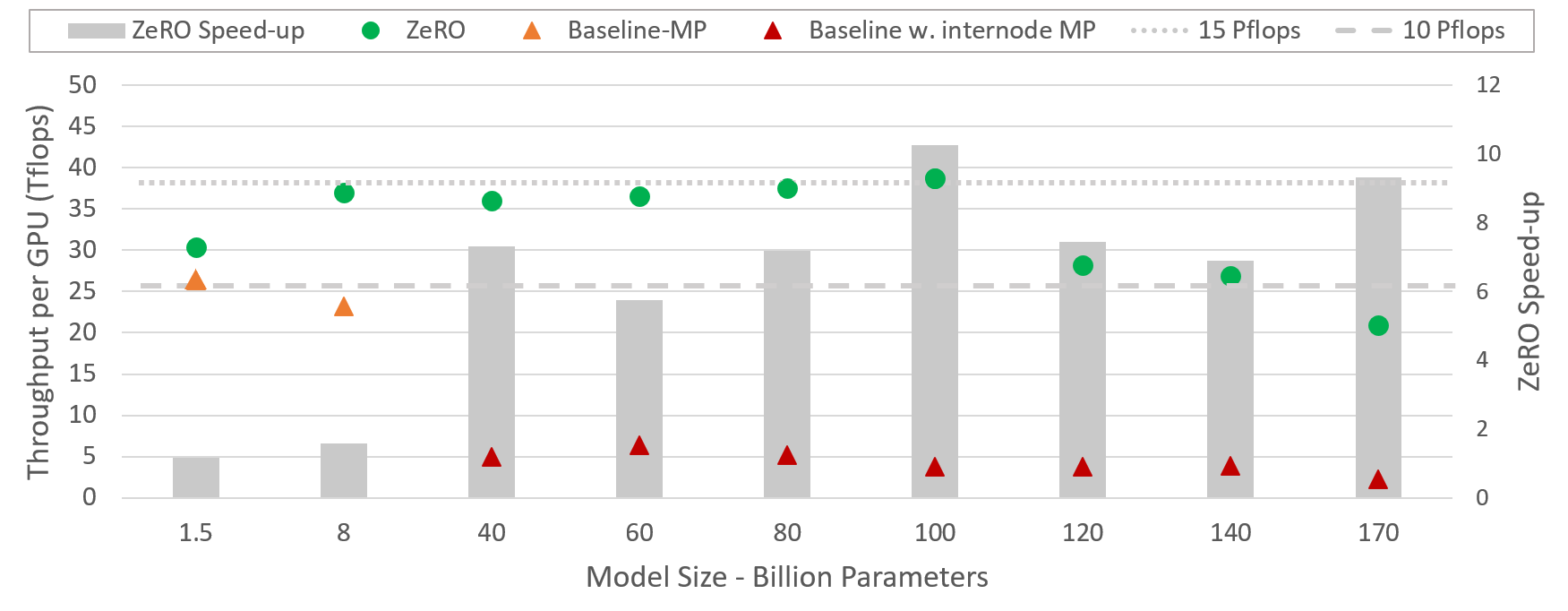
The figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of NVIDIA Megatron-LM) over using Megatron-LM alone.
Communication efficiency
Pipeline parallelism of DeepSpeed reduce communication volume during distributed training, which allows users to train multi-billion-parameter models 2–7x faster on clusters with limited network bandwidth.
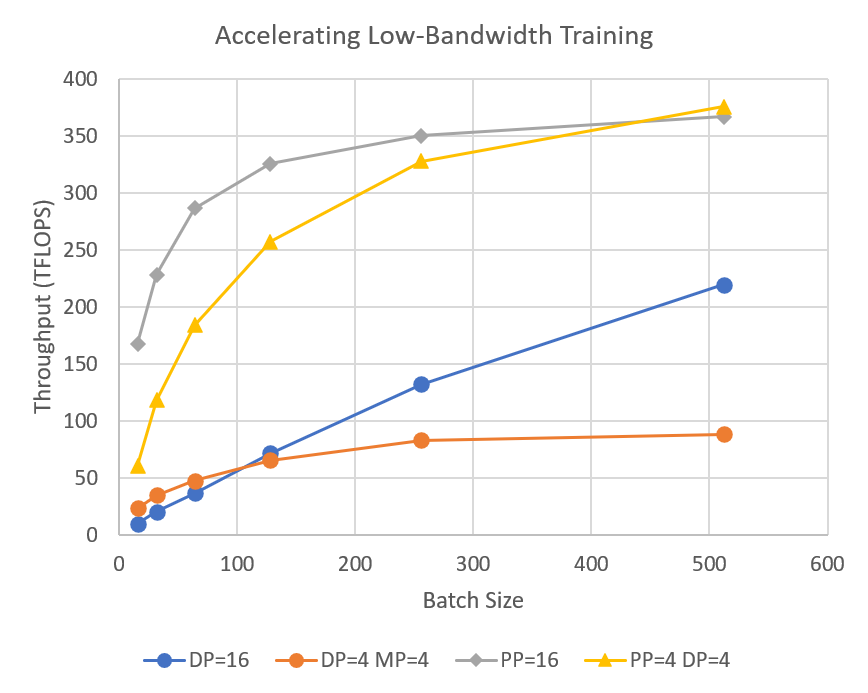
1-bit Adam and 1-bit LAMB reduce communication volume by up to 5x while achieving similar convergence efficiency to Adam, allowing for scaling to different types of GPU clusters and networks. 1-bit Adam blog post, 1-bit Adam tutorial, 1-bit LAMB tutorial.
Supporting long sequence length
DeepSpeed offers sparse attention kernels—an instrumental technology to support long sequences of model inputs, whether for text, image, or sound. Compared with the classic dense Transformers, it powers an order-of-magnitude longer input sequence and obtains up to 6x faster execution with comparable accuracy. It also outperforms state-of-the-art sparse implementations with 1.5–3x faster execution. Furthermore, our sparse kernels support efficient execution of flexible sparse format and empower users to innovate on their custom sparse structures. Read more here.
Fast convergence for effectiveness
DeepSpeed supports advanced hyperparameter tuning and large batch size optimizers such as LAMB. These improve the effectiveness of model training and reduce the number of samples required to convergence to desired accuracy.
Read more: Tuning tutorial.
Good Usability
Only a few lines of code changes are needed to enable a PyTorch model to use DeepSpeed and ZeRO. Compared to current model parallelism libraries, DeepSpeed does not require a code redesign or model refactoring. It also does not put limitations on model dimensions (such as number of attention heads, hidden sizes, and others), batch size, or any other training parameters. For models of up to 13 billion parameters, you can use ZeRO-powered data parallelism conveniently without requiring model parallelism, while in contrast, standard data parallelism will run out of memory for models with more than 1.4 billion parameters. In addition, DeepSpeed conveniently supports flexible combination of ZeRO-powered data parallelism with custom model parallelisms, such as tensor slicing of NVIDIA's Megatron-LM.
Features
Below we provide a brief feature list, see our detailed feature overview for descriptions and usage.
- Distributed Training with Mixed Precision
- 16-bit mixed precision
- Single-GPU/Multi-GPU/Multi-Node
- Model Parallelism
- Support for Custom Model Parallelism
- Integration with Megatron-LM
- Pipeline Parallelism
- 3D Parallelism
- The Zero Redundancy Optimizer (ZeRO)
- Optimizer State and Gradient Partitioning
- Activation Partitioning
- Constant Buffer Optimization
- Contiguous Memory Optimization
- ZeRO-Offload
- Leverage both CPU/GPU memory for model training
- Support 10B model training on a single GPU
- Ultra-fast dense transformer kernels
- Sparse attention
- Memory- and compute-efficient sparse kernels
- Support 10x long sequences than dense
- Flexible support to different sparse structures
- 1-bit Adam and 1-bit LAMB
- Custom communication collective
- Up to 5x communication volume saving
- Additional Memory and Bandwidth Optimizations
- Smart Gradient Accumulation
- Communication/Computation Overlap
- Training Features
- Simplified training API
- Gradient Clipping
- Automatic loss scaling with mixed precision
- Training Optimizers
- Fused Adam optimizer and arbitrary
torch.optim.Optimizer - Memory bandwidth optimized FP16 Optimizer
- Large Batch Training with LAMB Optimizer
- Memory efficient Training with ZeRO Optimizer
- CPU-Adam
- Fused Adam optimizer and arbitrary
- Training Agnostic Checkpointing
- Advanced Parameter Search
- Learning Rate Range Test
- 1Cycle Learning Rate Schedule
- Simplified Data Loader
- Curriculum Learning
- A curriculum learning-based data pipeline that presents easier or simpler examples earlier during training
- Stable and 2.6x faster GPT-2 pre-training with 8x/4x larger batch size/learning rate while maintaining token-wise convergence speed
- Complementary to many other DeepSpeed features
- Progressive Layer Dropping
- Efficient and robust compressed training
- Up to 2.5x convergence speedup for pre-training
- Performance Analysis and Debugging
- Mixture of Experts (MoE)
Contributing
DeepSpeed welcomes your contributions! Please see our contributing guide for more details on formatting, testing, etc.
Contributor License Agreement
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
Code of Conduct
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Publications
- Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '20).
- Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. (2020) DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '20, Tutorial).
- Minjia Zhang, Yuxiong He. (2020) Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping. arXiv:2010.13369 and NeurIPS 2020.
- Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He. (2021) ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840.
- Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, Samyam Rajbhandari, Conglong Li, Xiangru Lian, Ji Liu, Ce Zhang, Yuxiong He. (2021) 1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed. arXiv:2102.02888 and ICML 2021.
- Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, Yuxiong He. (2021) ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. arXiv:2104.07857.
- Conglong Li, Ammar Ahmad Awan, Hanlin Tang, Samyam Rajbhandari, Yuxiong He. (2021) 1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed. arXiv:2104.06069.
- Conglong Li, Minjia Zhang, Yuxiong He. (2021) Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training. arXiv:2108.06084.
Videos
- DeepSpeed KDD 2020 Tutorial
- Overview
- ZeRO + large model training
- 17B T-NLG demo
- Fastest BERT training + RScan tuning
- DeepSpeed hands on deep dive: part 1, part 2, part 3
- FAQ
- Microsoft Research Webinar
- Registration is free and all videos are available on-demand.
- ZeRO & Fastest BERT: Increasing the scale and speed of deep learning training in DeepSpeed.
- DeepSpeed on AzureML